
| ||||||||||||||||||


Discurso del profesor Eduard Hendrik HovyCon motivo de su investidura como Doctor Honoris Causa en Ingeniería Informática por la UNED | ||
|
|
||||||||||||||||||||||||

|
At this point, we children used the ensuing confusion to slip away from the room and escape the mandatory Bible reading. But one question kept coming back to me in the following years: what am I? Am I purely spiritual? Do I have a soul? If so, how could I prove it to my father’s satisfaction? So I decided to study Mathematics and Computer Science, subjects that surely address truths that cannot be denied. When starting my Ph.D. study, after reading some Philosophy and Psychology, I chose Artificial Intelligence, reasoning that although I certainly could not define what a soul is, if I could build a computer program that exhibited some signs of a soul, then surely I should be able to look inside its algorithms and its memory to gain understanding. I decided to specialize in human language processing, since it seemed to me that language is a wonderful window into the mind. It reflects not only your understanding of the world, but also your social relationships, and its production and comprehension reveal fascinating glimpses of how your mind works. Could a computer system working with language provide clues to what makes the human unique? An incident from my study illustrates the point. My thesis question was: Why and how do you say the same basic message differently to different people in different situations? To explore this question, I built a computer program that modeled in its memory a political event, and that included about two dozen parameters to model characteristics of the system as the speaker, of the hearer, and of their communicative situation. So, among others things, I could set the system to be pro or anti the political event, and I could make it forceful or insecure; and I could specify the hearer also to be pro or anti, and to be friendly or distant to the system, and socially dominant or subordinate to the system, and so on; and finally I could specify the situation to be formal or informal, and the amount of time to be much or little, and so on. Given all the possible combinations, the system could produce hundreds of variations of the same basic message about the political event. | ||
|
One day, I decided to model myself talking to my PhD advisor, assigning to him the opposite political opinions to mine. He is well-known to be a difficult, harsh personality, someone many students feared. To my surprise, once I activated the system, it produced no output! Not a word. I carefully tracked its reasoning. Yes, it had started with the main topic. It had found a detail to say. But since the hearer, my advisor, would not agree with the system’s opinions, a second topic was needed, to balance and soften the first one. But there was no time, and the hearer was pressing. The system next tried to find softening phrases, or alternative words, but to no avail. Therefore, it was better to search for another angle to the story. But the same pattern repeated itself. And again. Ultimately, for entirely understandable reasons, the system simply refused to speak. Now I had no idea that it could choose to do so! I spent 45 minutes confirming that nothing had gone wrong. My conclusion, initially, was that the system’s overall behaviour was more than just its individual rules…it seemed to act of its own accord. Somehow, from the complexity of its 14,000 lines of code, it did something psychologically perfectly natural, yet surprising. Is such emergence not analogous to how St. Thomas imagined the soul gives person-hood to the body? Did the system exhibit just a little glimpse of a real personality, of a soul? Or is it simply that the system’s rules were well-crafted, and folded together sensibly? What would you think, if your computer program did something psychologically natural, yet surprising to you? | ||
|
Well, I do not believe that one can determine the answer to the philosophical questions that interested St. Thomas using computer programs. At least not today. But fortunately the field of Human Language Technology (HLT) offers no shortage of fascinating challenges, enough to engage one for several lifetimes. And these challenges have real impact on society. You yourself have, even in the past few days, probably used at least one of its products. HLT is a compendium of interconnected efforts that, for example, have brought you: 1. Automated Speech Recognition: computer systems that convert the sounds you make when you speak into a stream of written words, which can then be processed further. How many times have you not cursed the ‘stupid computer’ that continues to misunderstand your most simple utterances when you want to book a flight on Iberia using the phone? 3. Machine Translation: computer systems that read sentences in one language and produce corresponding sentences in another, hopefully with the same meaning, and hopefully grammatically correctly. One of the oldest areas of Artificial Intelligence, this application has recently met with some success, and for common situations produces output that is perhaps not perfect but close enough for simple cross-language interactions.
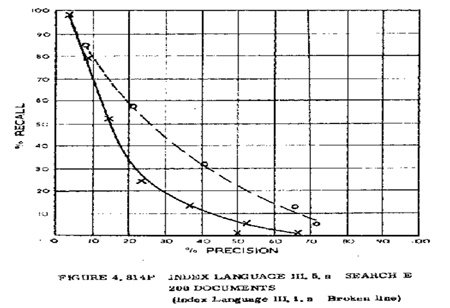
Since obtaining my Ph.D., I have been fortunate to work in several of these areas, collaborating with colleagues and students from around the world. It has been an immensely satisfying experience to uncover some hidden facts about language and the way people use it, and to slowly advance my own understanding of what makes us what we are. And, at the same time, to help bring to society some new capability that makes our lives easier. Consider, for example, the web. If an alien were to come to earth and say “show me the sum total of all the knowledge your civilizations have accrued over the centuries”, what would you show? Encyclopedia Britannica? No, you would show the web, starting with Wikipedia, and you would explain how one can access, in many of the world’s 7000 languages, information about almost anything known, both important and trivial: text, images, films, maps, numbers, all within an instant. Imagine how much engineering it takes to build the machinery that makes this possible. The field of Information Retrieval originated in the late 1950s, from computational work to help librarians. The earliest approaches employed lists of keywords, each keyword pointing to relevant documents, like the index cards anyone over the age of 30 knows from using a library in the past. But an imaginative experiment by a scientist named Cleverdon found that using any terms from the documents, as opposed to manually assigned thesaurus terms, synonyms, etc., achieved the best retrieval performance. That is, contrary to what one would think, including quite common words that seem too general to be useful still can help with search even in quite domain-specific documents. Cleverdon’s graph shows how many documents are retrieved correctly. With further right and up being better, the dashed line, showing results when including common words, is clearly superior to the solid line, which omits such words. Cleverdon wrote: | ||
|
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||

|
This vector defines a unique point in the space. Documents that have the same distribution (or ‘balance’) of words will lie nearby, while documents that contain very different words altogether will lie in a very different region. When you type in a query (a few words you are interested in), the system locates your query point in the vector space and finds all the documents nearby it, using specialized measures of distance. It returns them (actually, the pointers to them) in order of closeness. To make this work in practice —to locate and collect all the documents on the web, to store them into the vector space, to handle millions of users at the same time, and above all to make the process fast— researchers in Information Retrieval, and since the 1980s in companies like Yahoo, Google, Microsoft, and Baidu (in China), have spent an immense amount of person-hours of engineering. Sometimes even a small change can make a big difference. For example, the two owners of Google, Page and Brin, invented a new distance measuring algorithm that considered not only how close two documents are in the vector space, but also how popular each document has been with system users in the past. Including that information gave slightly more accurate results. Today Page and Brin are two of the richest people in the world, while earlier competing inventors, like the people who built Lycos, AltaVista, and other search engines, are working on other project. | ||
|
HLT is rich with similar histories, in Machine Translation, Speech Recognition, Question Answering, etc. All of them tell of talented scientists who love their subject and work very hard to engineer the absolute best solution they can find. Over the years, the general paradigm of research and engineering used in HLT is as follows:
| ||
|
We have at our disposal many results of this work. But as I mentioned earlier, these systems are not flawless. Despite years of deep exploration and careful engineering, the HLT systems being used today stubbornly refuse to become as good as humans are. Certainly, for certain tasks they may even outperform certain humans. But you have surely found among the responses Google gives you, or in the output of a language translation engine, or among the replies of a spoken language dialogue system on the phone, some puzzlingly stupid responses. Why is this? Almost all HLT systems today work with statistical combinations of words, and yet we all know as humans that we communicate about concepts. Merely working at the word level sometimes gives rather curious and amusing results. For example: Machine Translation: THE SPIRIT IS WILLING BUT THE FLESH IS WEAK We may think this is funny, but the tragedy is that the computer doesn’t even realize that! In HLT, we are facing a curious situation: we increasingly are able to build systems that learn to mimic some of the wonderful things people do with language, but we have less and less understanding of exactly how people do so. In particular, we cannot really describe what a fragment of language like a sentence means. Just like my PhD system whose rules were carefully crafted and sometimes even gave surprising results, the HLT systems of today work, but do not really understand what they are doing. If a librarian told you “oh, I don’t pretend to understand your question. Oh no. I simply try to match some of the words you give me to some of the books I’ve read” (which is what Google does), or a translator openly said “Who needs to understand? I’ll just look into my big book of translation phrases and paste together appropriate fragments in the other language” (which is what translation engines do), you’d surely not use their services? | ||
|
To address this sort of problem, HLT specialists a long time ago tried to model semantics — the science of meaning. They borrowed logical representations and modes of thought from Mathematical Logic, and tried to develop formalisms and rules of composition of symbols that allowed them to understand that a “willing spirit” cannot be alcohol and that zebras, when you find them, are animals, not words. They implemented these formalisms and rules in computer programs and tried to convert human-produced sentences into logical notations that accurately reflected the intended meaning. To date, this approach has not succeeded. The subtleties of word nuance, the complexities of composing individual words into larger structures of meaning, and the difficulties in capturing and working with interpersonal as well as factual knowledge make semantics an apparently impossible task. So, recently, HLT researchers have started to investigate applying statistics-based approximate methods to the problem of semantics. These methods have proven quite successful in handling the challenges of language, and form the basis of almost all of the systems used today. To approach the question of ‘statistical meaning’, if such a thing can be said to make sense, we are now trying the following approach. Rather than writing logical formulas using symbols that stand for concepts, as logicians do, we work with vectors of words that, taken together, stand for concepts. That is, rather than saying in the following proposition, Z represents a zebra in the world: … and create a vector like the Information Retrieval vectors for documents, including perhaps 1000 terms or even more: zebra = < (“Africa”.5015) (“lion”.4993) (“run”.4301) … (“quagga”.15) … > to model the concept zebra. Using modern techniques and online text, it is quite easy to build such sets of words (and by the way, it is also easy to discover that there is a second kind of “zebra”, one associated with words like “street”, “crossing”, “traffic light”, and “pedestrian”). It is also often simpler to use these word sets in HLT tasks than to use symbols whose meanings are essentially opaque to the computer. Placing concepts’ word vectors into a vector space, we apply distance formulas to measure how close concepts are to one another, and compare their vector space distances to people’s psychological judgments of concept similarity. In one test, HLT scientists use various forms of automated clustering algorithms to find which terms and which concepts fit into which contexts. For example, which meaning of “zebra” fits best into the sentence “he crossed the street at the _____”? Clearly, you can match the word vectors of the two “zebra” variants against the sentence’s words (and their own vectors) to see the answer. Techniques like Latent Semantic Analysis, a mathematical matrix operation that is also used in various other fields (such as structural engineering, where the same technique is called Principal Components Analysis, and face recognition) automatically finds the most important combinations of elements (called the eigenvalues) that together describe the phenomenon you’re studying. More sophisticated statistical techniques, such as Latent Dirichlet Allocation, are constantly being investigated by HLT engineers. Everyone wants to catch the next magic formula that, like Page and Brin, makes them billionaires! The impact of this shift in representation, from external models that require a human to understand to internal vectors of statistically related words, is having a profound effect in HLT, one whose implications are far from being understood. The possibilities, however, are exciting. Our basic and very crude model assumed that a metaphor appears when two different ‘worlds’ of experience are directly connected in a sentence. For example, in this bloated bureaucracy is driving me crazy. the fact that “bloated” is a physical property of bodies, and bureaucracies are not physical entities and therefore cannot be bloated, indicates to our approach the presence of a metaphorical interpretation of “bloated”. To find this automatically, we developed computer programs to collect, for each English word, all the other words that typically can connect together with it, in various grammatical combinations. For example, looking at millions of sentences, we discovered that the adjectives people typically use to modify “bureaucracy” include “government”, complex”, etc. The result is a vast compendium of meaning association vectors, one that took about two days to build running several hundred computers simultaneously. Now, when given the phrase “bloated bureaucracy”, the system is able quickly to recognize the expectation mismatch: the vector for “bureaucracy” does not accept words with meanings like “bloated”, and “bloated” does not modify words with meanings like “bureaucracy”. Our eventual goal is, of course, larger than discovering the presence of metaphors in sentences. In essence, some of us are trying to develop an algebra of semantics: a symbology and rules of semantic composition that mirror what people do in thought, analogous to the algebraic computations that physicists do when they try to mirror what nature does in the world. Both Leibnitz and Boole (the inventor of Boolean logic) held this dream. Today, if you want to determine whether “the zebra crossed the road” refers to an animal or a street crossing, you have to perform some sophisticated analysis. Just matching simple word vectors will give you the wrong answer! How can we define rules of concept combination that compose the vectors for “zebra”, “cross”, and “road” in such a way as to produce a new vector that clearly and unambiguously represents that we are thinking of an animal walking across a street? Imagine if you could define such rules of composition —an algebra— and then compute larger, complex, meanings by composing smaller ones! From words to sentences to paragraphs to whole documents, you’d have something much more expressive and exact to place into your vector spaces and internal representations than words, and using this obtain much more accurate results for Information Retrieval, Machine Translation, and so on. | ||
|
This is a very exciting idea. If HLT can succeed in this quest, it will have major impacts on the degree of accuracy of many application systems that HLT, and Artificial Intelligence in general, have developed. It will enable many more, and more complex, computer systems, ones that much more closely mimic what people do when they communicate and reason. Now it is almost certain that simple word vectors are not adequate for the challenge. So we are investigating other structures, including more-general vectors called tensors, that are used by quantum physicists. And HLT scientists are investigating various forms of concept composition rules, using machine learning and other techniques, in an exciting race to uncover one of the deepest mysteries of intellectual thought: how to represent meaning precisely, in a scientific and measurable way. While the answer, when it comes to us, will certainly not imbue computer systems with souls, the development of systems increasingly able to reason like humans do, to understand and explain themselves, will provide some very interesting material for Thomas Aquinas and other people interested in the nature of the human being. Lord Rector of the National University of Distance Education, I hope to have shared with you the excitement and potential of the investigations of how one can process language on a computer, and what might result from these studies. I hope that these results will produce computer systems that more accurately and effectively assist in our lives. If they succeed, they will inevitably raise questions about what makes us humans special. Thank you. | ||
| DISCURSO EDUARD H. HOVY | ||
|
Madrid, enero de 2013 | ||