
| ||||||||||||||||||


LAUDATIO Eduard Hendrik HovyDoctor Honoris Causa por la UNED 2013 Mª Felisa Verdejo Maillo. Catedrática de Lenguajes y Sistemas Informáticos de la UNED | ||
|
|
||||||||||||||||||

|
Introducción En 1991, año en que se publicó en el BOE la creación de la Escuela Universitaria de Informática de la UNED, las dos asociaciones que agrupaban mayor número de profesionales de informática, la Association for Computing Machinery (ACM) junto con el capítulo del IEEE –Computer Science (IEEE-CS) publicaron el resultado de los trabajos de un grupo conjunto que habían establecido en el 88, para definir el Computing Curricula (A.B.Tucker Ed) (1) . Este informe tuvo un alto impacto internacional, e inspiró una buena parte de los planes de estudios de informática en la década de los 90. En ese documento se recordaban los tres pilares que constituyen la informática como disciplina : teoría, abstracción (modelado) y diseño, basados respectivamente en las raíces interdisciplinares que la sustentan: matemáticas, ciencias experimentales e ingeniería. En el 2001, se creó la Escuela Superior de Ingeniería Informática de la UNED. En ese año, el grupo de trabajo ACM & IEEE-CS publicó una nueva referencia, el Computing Curricula-2001, en donde se dedicaba un apartado a enumerar los enormes cambios tecnológicos que se habían producido en solo una década, dibujando un nuevo paisaje para la informática que hacía necesario replantear el alcance de la enseñanza de la disciplina, ampliándola para reconocer la emergencia de 5 subdisciplinas: Computer Engineering, Computer Science, Software Engineering, Information Systems, Information Technology. En el documento se analizan en detalle los cambios tecnológicos (baste recordar que en el 91 la Web era poco menos que una idea en la mente de sus creadores), pero además se resaltan los cambios sociales y económicos propiciados por las tecnologías de la información y las comunicaciones, en todos los ámbitos de la actividad humana. En la sociedad de la información, las personas actúan e interactúan mediante sistemas informáticos, de ahí la importancia que cobra el diseño de sistemas centrados en el usuario, más aún en todos los aspectos de acceso a la información y la comunicación interpersonal o en grupo, en una buena parte, expresadas en lenguaje natural. Así mismo, se destaca que el ejercicio de la profesión informática, conlleva el trabajo en equipo, a menudo con carácter interdisciplinar, y por tanto se recomienda que desde el principio de los estudios, se fomenten estas capacidades a través de un aprendizaje teórico-práctico articulado mediante la realización de proyectos. Tras doce años de funcionamiento de la E. T. Superior de Ingeniería Informática de la UNED, hoy tenemos el honor de celebrar la investidura de nuestro primer doctor honoris causa, y para ello contamos con un informático, cuya carrera profesional ilustra los rasgos subrayados en las recomendaciones curriculares, y que en unas breves pinceladas voy a describir a continuación. | ||
|
SEMBLANZA Orígenes Eduard Hovy, nació en Sudáfrica, graduándose en Matemáticas en la Rand Afrikaans University en marzo de 1979. Obtuvo su master en Computer Science en la Universidad de Yale (USA) en 1982. Con un marcado perfil interdisciplinar, con raíces en los campos de Inteligencia Artificial (procesamiento de lenguaje natural, planificación y aprendizaje) , Psicología (ciencia cognitiva), Lingüística (discurso, pragmática y semántica), Teoría de la Computación y Filosofía, el Profesor Eduard Hovy es uno de los investigadores reconocidos como fundadores del área de Procesamiento Automático del Lenguaje Natural. Su producción científica ha sido fundamental en diversos temas, destacando su contribución seminal tanto en generación de lenguaje natural como en ontologías y semántica léxica. Su tesis doctoral, PAULINE (Planning and uttering language in Natural Environments), defendida en la U. De Yale en 1987, introdujo la pragmática como una dimensión clave para la generación automática del lenguaje natural, modelando el problema en términos de objetivos de comunicación, que se refinan en un nivel intermedio en objetivos retóricos para capturar rasgos tales como formalidad, simplicidad, detalle, parcialidad, respeto, ect . Al modelar el problema como una resolución de objetivos, se puede formalizar la generación de textos mediante planes y estrategias; así, un sistema, partiendo de una misma representación conceptual del contenido, podría construir diferentes textos adaptados a un contexto pragmático específico, teniendo en cuenta además a los interlocutores. El contexto se modelaba en términos de un amplio conjunto de características ( pares atributo-valor) , por ejemplo para las condiciones de situación se consideraba entre otros el tiempo (mucho, algo, poco) el tono (formal, informal, festivo..), en la caracterización de los hablantes: el conocimiento y grado de interés en el tema, la opinión sobre el tema (buena, neutral, mala), el estado emocional, ect. El proceso de planificación se llevaba a cabo de forma dinámica, (limited-commitment), mezclando las fases de planificación y realización, que de alguna manera también es un modelo acorde con la investigación en psicolingüística. La planificación en este caso sigue una estrategia de resolución, mezcla de prescripción (top-down ) y restricción (seleccionar entre alternativas, en forma bottom-up, para manejar objetivos conflictivos). Etapa de Consolidación Al terminar su tesis, tras una breve estancia en los laboratorios de investigación de IBM Alemania, se incorporó en 1990 al Information Sciences Institute, asociado a la University of Southern California (ISI-USC). Quiero resaltar dos aspectos acerca de esta institución, primero el papel fundamental y pionero que jugó en la creación y la implementación de Internet, y segundo, su vocación de institución puente entre la Universidad y la Industria, para realizar una investigación de calidad financiada con un partenariado público-privado. En el ISI, el Dr. Hovy, ha creado un equipo dinámico y puntero en Human Languages Technologies, involucrado en estos veinte años en mas de 75 proyectos, financiados en convocatorias competitivas de diferentes organismos como la NSF o el DARPA, y de la mano de laboratorios de investigación de empresas como BBN o IBM. A lo largo de su carrera, ha demostrado su liderazgo trabajando en cooperación con otros equipos de investigación de primera línea, en grandes proyectos que han sido referencia en cada una de las temáticas, entre los que destacaremos: Diseño e implementación de sistemas: • PANGLOSS: Un sistema de traducción automática basado en Interlingua. En colaboración con J. Carbonell y S.Nirenburg (CMU), y Y. Wilks (NMSU) (1989-1994) • The Webclopedia: Sistema automático de Pregunta-Respuesta sobre la wb 2000-2003. 2º puesto (de 35) en la competición del TREC 2000 Teoría e infraestructura de evaluación de sistemas: • BE Automated Summarization Evaluation Package, utilizado por el National Institute of Standards (NIST) para evaluar a los sistemas participantes en las competiciones del TAC. Licencia de distribución pública. | ||
|
Modelado semántico y metodologías para la creación de recursos anotados • The OntoNotes. Diseño de una ontología capturando los niveles léxico, semántico y conceptual, y creación de un recurso (corpus multilingüe anotado) . En cooperación con Dr. Ralph Weischedel (BBN), Prof. Mitch Marcus (UPenn) y la Prof. Martha Palmer (U of Colorado). Distribuido por el LDC. • RACR-ISI: Reader and Contextual Reasoner. Dirigido por IBM Yorktown Heights, con participación de la U. of Texas (Austin), CMU, y la U of Utah. May 2009. Creación de grandes bases de conocimiento para su utilización en análisis e inferencia textual. Trayectoria investigadora | ||
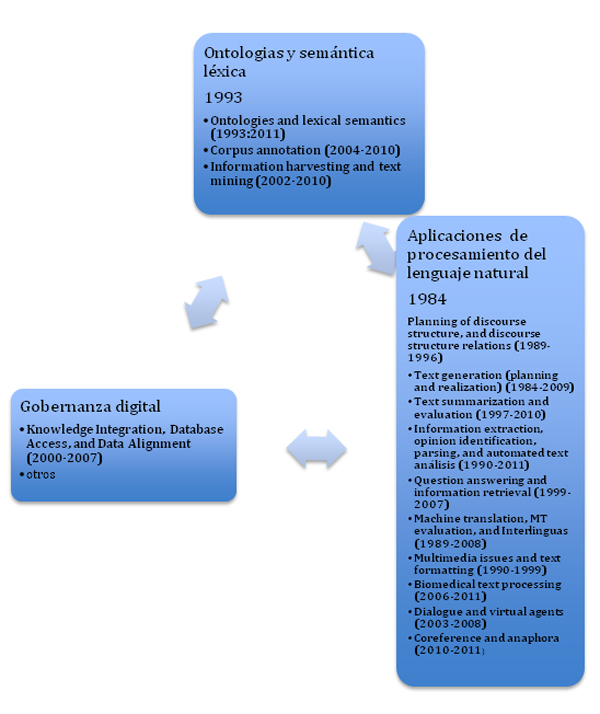 | ||
|
En Ontologías La definición de notaciones y el desarrollo de herramientas para la representación semántica superficial, que sirven para anotar corpus textuales multilingües de gran volumen, a nivel semántico. Esta línea se articuló mediante varios proyectos, como el Ontonotes mencionado previamente, en donde se trataron 7 lenguas entre ellas el inglés, chino y árabe. La base de la notación proviene de la ontología Omega (2003), creada por su equipo en el ISI, mediante una combinación de técnicas de mezclado y enriquecimiento de diversas fuentes , tales como otras ontologías a diferente nivel de representación y granularidad léxico-semántica-conceptual (Princeton's WordNet, NMSU's Mikrokosmos y ISI’SENSUS), el conocimiento extraído de textos y de las relaciones de interdependencia en diccionarios. Omega tiene más de 120.000 términos conceptuales, y varios millones de instancias y ha sido un recurso ampliamente utilizado en traducción automática, extracción e integración de información. En Procesamiento del lenguaje natural • El diseño y desarrollo de tecnología para un proceso masivo de textos, con el fin de extraer grandes cantidades de información tanto a nivel conceptual como a nivel de instancias. En un gran numero de proyectos desde 1996, el Dr. Hovy, junto con sus estudiantes y colaboradores, ha desarrollado una serie de extractores para llevar a cabo minería de textos, y construir así grandes colecciones de aserciones acerca de personas, localizaciones y objetos. Esta información factual, almacenada en una base de datos, está conectada con la ontología Omega. En uno de sus recientes proyectos “aprender leyendo”, las técnicas de análisis sintáctico, semántico e inferencia se combinan para crear automáticamente una base de datos a partir de la lectura de textos (en varios formatos, incluyendo páginas web) de Biología y Química de enseñanza secundaria, de forma que el sistema puede contestar a preguntas de exámenes de este nivel de enseñanza. En esta línea cabe señalar su colaboración en el sistema WATSON. (Watson es un sistema informático de inteligencia artificial que es capaz de responder a preguntas formuladas en lenguaje natural, desarrollado por IBM. A lo largo de tres días en febrero de 2011, para probar sus capacidades reales, participó en un concurso de televisión estadounidense Jeopardy!, derrotando a sus dos oponentes humanos, campeones hasta el momento)
| ||
|
Los resultados de su trabajo han dado lugar a más de 250 publicaciones ( índice H de 55) entre las que se incluyen 6 libros, 26 artículos en revistas, 179 artículos en los congresos de primera línea, y 22 capítulos de libros; software de aplicaciones, e infraestructura de evaluación automática para diferentes tipos de tareas de PLN (utilizadas en las competiciones internacionales del DUC 2005-2007 y el TAC 2008, organizadas por el NIST), así como el establecimiento de una amplia red de colaboradores (por ejemplo en la conocida base de datos de DBLP aparecen 174 publicaciones en coautoría con 28 autores diferentes, coincidiendo con cada uno en más de 5 publicaciones distintas) Esta estrategia de colaboración es clave para acometer la complejidad y escalabilidad de los retos que hoy plantea la investigación en estas disciplinas. Articulación profesional de la disciplina Es de destacar su labor para promover y establecer una comunidad científica a nivel mundial , siendo su participación decisiva para estructurar con cobertura internacional, la Association for Computational Linguistics (ACL), inicialmente creada en USA. Hoy, con un ámbito global es la organización científica de referencia en esta disciplina relativamente joven . También ha sido Presidente de la International Association of Machine Translation (IAMT). Ha sido conferenciante invitado y panelista en numerosos congresos; organizador, y presidente del comité de programa en numerosas ocasiones. Destaca especialmente la actividad del Profesor Hovy en China y en Europa, en donde mantiene una presencia constante de apoyo a los grupos de investigación. Siempre ha considerado esencial articular el trabajo científico con la sociedad, y con los responsables de la política científica y ha dedicado su tiempo y energía a trabajar y promover iniciativas en pro de políticas científicas que favorezcan la cooperación y el desarrollo de recursos tecnológicos para el tratamiento de todas las lenguas. En particular siempre ha apoyado a la comunidad investigadora en España, con la que mantiene un amplio contacto desde su primera visita a la U. Autónoma de Madrid en 1994. La relación ha sido continua en el caso del grupo de investigación de NLP&IR de la UNED desde el año 1995, cuando nos respaldó para la organización del congreso del ACL 97 en la UNED, el primero que se celebró fuera de Estados Unidos, y que fue un paso clave para dar visibilidad a los grupos españoles y europeos en la comunidad internacional. Hoy nos acompañan colegas de la UPV, de la U. De Alicante, de la UPC, de la U. de Barcelona, de la U. Complutense y de la UNED a los que E. Hovy ha acogido en su grupo de investigación del ISI-USC en Marina del Rey en la última década. En su brillante y amplísima trayectoria investigadora ha realizado contribuciones muy relevantes en otras temáticas como por ejemplo: • promoción y organización de campañas de evaluación internacionales, para crear estándares, medidas y transferir resultados a productos. Quiero mencionar aquí la serie de campañas Question Answering for Machine Reading Evaluation (QA4MRE), coorganizadas por A. Peñas (UNED) y E. Hovy (ISI_USC). • gobernanza digital (E-Government), habiendo sido presidente de la Digital Government Society of North America. Ha participado activamente en diversos eventos para una colaboración en este campo entre USA y la EU, entre ellos el proyecto con el consorcio europeo QUALEG con el objetivo de facilitar la interacción entre organismos gubernamentales y el ciudadano. El trabajo de su grupo en el ISI se centró en el diseño y desarrollo de un sistema para clasificar correo electrónico, extrayendo opiniones, y partes implicadas . Sobre este tema es coautor del libro Digital Government: Advanced E. Government Research and Case Studies, Springer-Verlag 2007. | ||
|
Ha sido co-organizador y co-editor de informes estratégicos sobre el estado del arte en temas especializados, como por ejemplo el Report in Multilingual Information Management , encargado por la National Science Foundation, y resultado de una serie de reuniones multilaterales de expertos celebradas en Granada (Mayo 1998) y en Montreal (Agosto 1998). Ha participado como asesor (Scientific Advisory Board) en gran número de consorcios europeos y organismos punteros en investigación en todo el mundo. Colabora con editores internacionales en la definición de un nuevo modelo para las publicaciones y difusión científica, encabezando el comité del Elsevier Grand Challenge. Este evento fue un concurso de ideas, plasmadas en un prototipo software, dirigido a mejorar el acceso y el uso del contenido científico que se presenta en los artículos de revistas on-line en el campo de Ciencias de la vida. El ganador fue un prototipo que procesa artículos, identificando en los textos las menciones a cualquier gen, presentando dinámicamente al lector información adicional a diferente nivel de detalle y especialización. Formación de investigadores El profesor Hovy ha iniciado una nueva etapa de su carrera en la Carnegie Mellon University en Octubre del 2012, incorporándose al prestigioso “Language Technologies Institute”, desde dónde seguiremos contando con su colaboración. A modo de conclusión Lo reseñado aquí es un brevísimo resumen de la trayectoria del Dr. Hovy, como investigador pionero, como impulsor de nuevas áreas de investigación ligando la visión tecnológica con otras disciplinas relacionadas con el lenguaje, como formador de investigadores, como científico preocupado por la dimensión internacional y social de la ciencia, como promotor de asociaciones para fomentar la cohesión de las disciplinas científicas y favorecer la visibilidad de la investigación en los diferentes países, como profesional responsable involucrándose en la estructuración y financiación cooperativa de la investigación a nivel internacional. Sudafricano de nacimiento, con raíces familiares en Holanda, suizo de nacionalidad por su madre, con una carrera profesional centrada en Estados Unidos, con un buen número de discípulos chinos y con una compañera japonesa, nos demuestra bien su talante de ciudadano de la sociedad globalizada que la tecnología informática ha propiciado en tan solo unas décadas, y a la que ha contribuido de forma significativa las tecnologías del lenguaje y el acceso a la información multilingüe. Por todo ello, es un honor y una satisfacción para nuestra Escuela contar con Ed Hovy como miembro distinguido de la comunidad informática de la UNED. No quiero terminar sin evocar con cariño al Profesor Mira, Catedrático de Inteligencia Artificial de la UNED, con quien tuvimos la suerte de recorrer desde el principio, el camino en esta Escuela, y con quien creamos el programa de doctorado conjunto de Inteligencia Artificial y Lenguajes. Su espíritu abierto y constructivo nos acompaña siempre. Profesor Hovy, en nombre de todos los colegas y de los compañeros de la UNED, a quienes represento en este abrazo, bienvenido y gracias por estar entre nosotros. | ||
| (1)Los documentos mencionados pueden encontrarse en esta enlace | ||
|
| ||
|
Madrid, enero de 2013 | ||